
Object Detection
Published:
Object Detection
- Object Detection
- Common Object Detection Algorithms
- Bounding Box Regression
- Faster R-CNN
- YOLO (You Only Look Once)
Object Detection
- Object detection is a computer vision technique that allows us to identify and locate objects in an image or video.
- This is a complex task, because the size, shape, and position of objects can vary significantly.
Common Object Detection Algorithms
There are many object detection algorithms, but some of the most popular include:
- Region Proposal + Deep Learning Classification: This approach uses a region proposal algorithm to identify potential objects in an image, and then uses a deep learning classifier to classify the objects.
- R-CNN (Selective Search + CNN + SVM)
- Fast R-CNN (Selective Search + CNN + ROI)
- Faster R-CNN (Region Proposal Network + CNN + ROI)
- Single Shot Detectors: These algorithms use a single neural network to predict the bounding boxes and class labels for all objects in an image.
- YOLO (You Only Look Once)
- SSD (Single Shot MultiBox Detector)
Bounding Box Regression
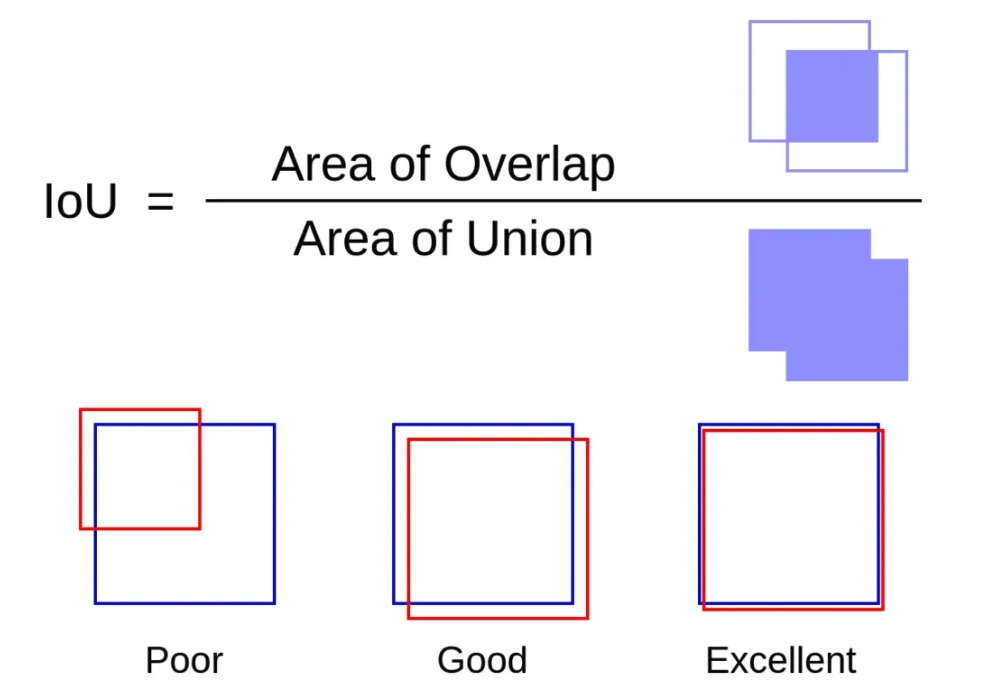
IOU (Intersection over Union)
- Intersection over Union (IOU) is a measure of the overlap between two bounding boxes.
- It is calculated as the area of the intersection of the two boxes divided by the area of their union.
- High IOU values indicate a high degree of overlap between the boxes. \(IoU = \frac{Area of Overlap}{Area of Union}\)
Bounding Box Regression
- We using (x, y, w, h) to represent the bounding box. x, y are the coordinates of the center of the box, and w, h are the width and height of the box.
- Red box P is the predicted box, and green box G is the ground truth box.
- We need to find a transformation that maps the predicted box P to a box G’ which is closer to the ground truth box G. Find a mapping function: \((G'x, G'y, G'h, G'w) = f(Px, Py, Ph, Pw), where (G'x, G'y, G'h, G'w) \approx (Gx, Gy, Gh, Gw)\)
There is a easy way to do the bbox regression is: offset + scale.
- Offset: \(G'_x = P_{w}d_x(P)+P_x\) \(G'_y = P_{h}d_y(P)+P_y\)
- Scale: \(G'_w = P_{w}e^{d_w(P)}\) \(G'_h = P_{h}e^{d_h(P)}\)
So given predicted box P and ground truth box G, we need to learn the (dx, dy, dw, dh) to minimize the loss function.
Faster R-CNN
- Convolutional Layers: Extract features from the input image.
- Region Proposal Network (RPN): Generate region proposals (bounding boxes) for objects in the image.